Mac系统打包创建ISO
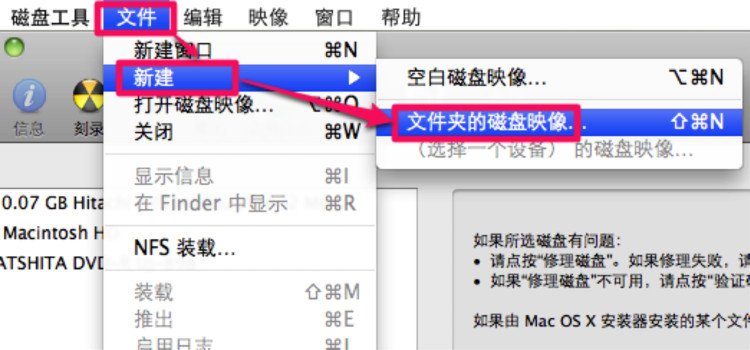 运行磁盘工具,选择文件,新建,文件夹的磁盘映像运行磁盘工具,选择文件,新建,文件夹的磁盘映像,选择要做成ISO的文件夹,点击映像。映像格式选择“DVD/CD主映像”,点击存储后会生成一个cdr文件。运行磁盘工具,选择文件,新建,文件夹的磁盘映像
选择要做成ISO的文件夹,点击映像。
映像格式选择“DVD/CD主映像”,点击存储后会生成一个cdr文件。
开一个终端,运行红线下的命令,就能把cdr转换成iso了。hdiutil makehybrid -iso -joliet -o 生成文件.iso 打包文件.cdr
运行磁盘工具,选择文件,新建,文件夹的磁盘映像运行磁盘工具,选择文件,新建,文件夹的磁盘映像,选择要做成ISO的文件夹,点击映像。映像格式选择“DVD/CD主映像”,点击存储后会生成一个cdr文件。运行磁盘工具,选择文件,新建,文件夹的磁盘映像
选择要做成ISO的文件夹,点击映像。
映像格式选择“DVD/CD主映像”,点击存储后会生成一个cdr文件。
开一个终端,运行红线下的命令,就能把cdr转换成iso了。hdiutil makehybrid -iso -joliet -o 生成文件.iso 打包文件.cdr